

Veel wiskunde voor AI en machine learning werd in de jaren 90 uitgevonden, maar het duurde bijna twee decennia voordat AI/ML relevant werd. Kun je een paar redenen bedenken waarom dat zo was? Gegevens en rekenkracht waren de belangrijkste factoren die de ontwikkeling van AI vertraagden. Zoals je misschien vaak hebt gehoord met de uitdrukking “Data is het nieuwe goud,” kunnen we het belang van gegevens niet genoeg benadrukken. Naarmate we in de tijd vooruitgaan, produceren we steeds meer data. Tegenwoordig produceren zelfs traditionele apparaten zoals koelkasten en televisies veel gegevens met behulp van IoT-sensoren. Het beheren en benutten van gegevens wordt een enorme taak in de voortdurend groeiende wereld van data. Laten we eens nader kijken naar het belang van gegevens, vooral vanuit het ML/AI-perspectief.
Data voor AI
In 2010 werd een uitdaging genaamd ImageNet Large Scale Visual Recognition Challenge (ILSVRC) gelanceerd, en in die uitdaging werd de ImageNet-dataset geïntroduceerd. ImageNet was de eerste grootschalige dataset die werd gebruikt om de kracht van moderne neurale netwerken goed te demonstreren. De ImageNet-dataset was de eerste echte grootschalige afbeeldingsdataset waarmee we de prestaties van de Deep Neural Networks konden testen, ontwikkeld in de vroege stadia van de AI-revolutie. Maar voordat we verder gaan, moeten we ons afvragen waarom het bijna twee decennia duurde om een dataset zoals ImageNet te creëren. De grootste uitdaging bij het maken van een dataset is tijd, middelen en kosten. Bijvoorbeeld, de ImageNet-dataset bevat momenteel ongeveer 14 miljoen afbeeldingen die behoren tot 20.000 categorieën. Elke afbeelding is handmatig gelabeld in de dataset. Het zou jaren hebben geduurd om deze afbeeldingen te verzamelen, laat staan om ze handmatig te labelen. Het creëren van een dataset is een zeer tijdrovend en kostbaar proces; daarom duurde het 20 jaar voordat AI van de grond kwam. Afhankelijk van het model kost het enkele honderden tot duizenden dollars om te trainen op de volledige ImageNet-dataset. Daarentegen is het labelen van gegevens veel duurder. Bij de startup Scale.ai uit Silicon Valley kost het labelen van een dataset van 20k–50k tot wel $320.000 voor slechts één dataset. De afgelopen jaren zijn er betere en goedkopere tools voor het labelen van gegevens gekomen, maar het komt nog lang niet in de buurt van de trainingskosten. 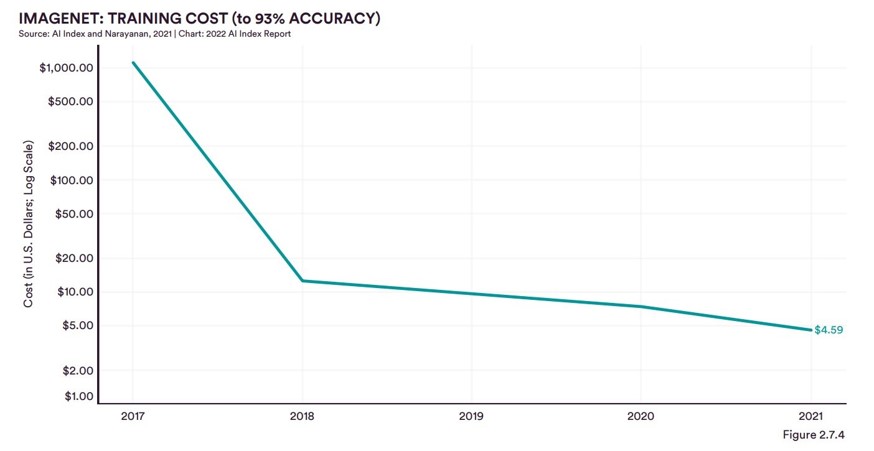
Uitdagingen voor huidige AI
Het is bijna tien jaar geleden sinds de release van VGG, een beroemde CNN-architectuur die voor het eerst aantoonde dat het mogelijk was om nauwkeurige beeldherkenning te doen met een diep netwerk en kleine convolutionele filters. Sindsdien hebben we een lange weg afgelegd in de ontwikkeling van modelarchitecturen en het creëren van nieuwe en diverse datasets. VGG was het eerste netwerk dat een fatsoenlijke prestatie behaalde in de ImageNet-uitdaging (classificatie op de ImageNet-dataset) en zette AI voor de massa op de kaart. VGG inspireerde een hele reeks nieuwe architecturen, maar er zijn nog steeds slechts een handvol technieken en modellen die daadwerkelijk kunnen werken met kleinere datasets. Tot op de dag van vandaag blijft data het grootste probleem voor bijna elk probleem. Er zijn maar een paar grootschalige datasets beschikbaar om nieuwe modelarchitecturen te testen, maar het vinden van branchespecifieke gegevens is bijna net zo moeilijk als 10 jaar geleden.
Om het probleem van grote datasets enigszins te verlichten, gebruiken praktische AI-implementaties het concept van transfer learning. Volgens Wikipedia is Transfer learning (TL) een onderzoeksvraag binnen machine learning (ML) die zich richt op het opslaan van kennis die is opgedaan bij het oplossen van het ene probleem en deze toe te passen op een ander, maar gerelateerd probleem. (1) Dit wordt bereikt door de lagen van een bestaand model te hergebruiken, behalve de laatste paar lagen. De initiële lagen van een model halen vergelijkbare soorten informatie uit de afbeeldingen, dus door deze lagen te bevriezen, besparen we tijd en middelen.
Niet alleen hebben we veel gegevens nodig, maar de nieuwe trend draait om *goede* gegevens. Er is veel data beschikbaar op het internet, maar het meeste is verspreid en daarom voor ons vrijwel nutteloos. Een andere uitdaging die bedrijven vaak tegenkomen, is dat de gegevens op internet voornamelijk worden gebruikt voor het creëren van een algemeen AI-model. De openbare gegevens op internet zijn branche-agnostisch, en daardoor vaak nutteloos voor de industrie. Dit is een van de belangrijkste redenen waarom de industrie achterloopt bij het adopteren van AI vergeleken met de academische wereld. Behalve een paar onderzoeksbedrijven zoals Google’s DeepMind en OpenAI, heeft bijna geen enkel bedrijf de gegevens om systemen te bouwen die kunnen opschalen. 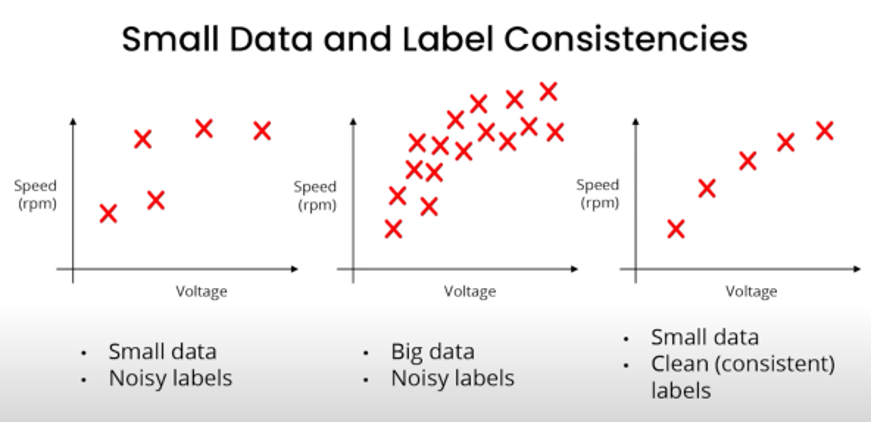
Maar wat is goede data?
We hebben het veel gehad over het belang van data, maar we moeten dieper ingaan en praten over de details van gegevens. Over het algemeen bestaan AI-systemen uit twee hoofdonderdelen: Code en Data. In de meeste problemen buiten het consumenteninternet bestaat Big Data niet, dus we hebben ofwel AI-oplossingen nodig die kunnen werken met kleine datasets, of we hebben datasets nodig die schoon zijn en de verdeling van de volledige populatieset vertegenwoordigen. In een recente toespraak van Dr. Andrew Ng (pionier in AI) sprak hij over goede data en waarom het belangrijker is om goede data te hebben dan grote hoeveelheden data. Goede data:
- De essentie van de gevallen dekt (goede inputverdeling X). De steekproefverdeling moet nauw aansluiten bij de werkelijke populatieverdeling.
- Heeft nauwkeurige labels (Hoogwaardige y). Zelfs een paar verkeerde labels kunnen de leervermogens van het model aanzienlijk verstoren, wat leidt tot foutieve resultaten in kritieke situaties.
- Bevat tijdige feedback van de implementatie. Om het model aan te passen aan de veranderende dataset.
- Goede governance (redelijk vrij van vooringenomenheid; voldoet aan privacyregels; data lineage en naleving van regelgeving). Om de privacy te beschermen en te voorkomen dat machines bevooroordeeld raken tegenover bepaalde groepen mensen.
Een reeks praktijken die gericht is op het betrouwbaar en efficiënt implementeren en onderhouden van machine learning-modellen in productie wordt MlOps genoemd. De term is een samenstelling van “machine learning” en de continue ontwikkelingspraktijk van DevOps in de softwarewereld. De belangrijkste taak van MlOps is ervoor zorgen dat er consistent hoogwaardige gegevens zijn in alle fasen van de ML-projectlevenscyclus.
Onze aanpak
Bij SkyeBase werken we vaak met industriële afbeeldingen; het verkrijgen van dergelijke gegevens is altijd moeilijk. SkyeBase houdt zich bezig met een grote verscheidenheid aan industriële afbeeldingen die afkomstig zijn van locaties zoals havens, boorplatforms, bruggen en vele andere industriële locaties. Voor de operaties van SkyeBase is de primaire gegevensbron onze eigen verzameling door middel van verschillende drones die in verschillende omgevingen kunnen vliegen (binnen, buiten, onder water, etc.). Zelfs met alle beschikbare hardware blijft het verzamelen van gegevens moeilijk. Vaak zijn de verzamelde gegevens niet voldoende om een schaalbaar model te bouwen. Afhankelijk van de taak moeten we soms zwaar leunen op webscraping voor gegevensverzameling. Het grootste probleem met gegevens afkomstig van scraping is dat ze niet schoon zijn en vaak afbeeldingen van lage kwaliteit bevatten. De volgende grote taken bij gegevensverwerking zijn sorteren en annoteren. We bouwen momenteel ons eigen annotatietool om een gestroomlijnde workflow op te zetten tussen ons inspectieplatform I-Spect en de verzamelde gegevens. Naarmate SkyeBase zijn activiteiten uitbreidt, zullen we een *data lake* creëren om al onze gegevens te centraliseren. Om het probleem van lage resolutie op te lossen, maakt SkyeBase gebruik van de kracht van GAN’s (Generative Neural Networks). GAN’s zijn een specifiek soort neuraal netwerk dat in staat is om nieuwe gegevens te genereren op basis van de gradient. GAN’s kunnen worden aangepast om nieuwe afbeeldingen te genereren, ruis te verwijderen of afbeeldingen met een hoge resolutie te maken. De gegevens die worden gegenereerd door superresolutienetwerken zoals REAL-ESR GAN zijn uitstekend en kunnen gemakkelijk worden gebruikt voor productiesystemen. Het gebruik van deze superresolutienetwerken is bijzonder nuttig geweest voor de operaties van SkyeBase.
