
A lot of math for AI and machine learning was invented in the 90s, but it took almost two more decades for AI/ML to become relevant. Can you think of a few reasons why that’s the case? Data and processing power were the primary factors that forestalled the AI’s development. As you may have often heard the phrase “Data is the new gold,” we can’t stress enough the importance of data. As we progress in time, we are constantly producing more and more data. These days even traditional devices like refrigerators and TVs are producing a lot of data with the help of IoT sensors. Managing and utilizing data properly becomes a herculean task in the ever-growing world of data. Let’s have a detailed look at the importance of data, especially from the ML/AI perspective.
Data for AI
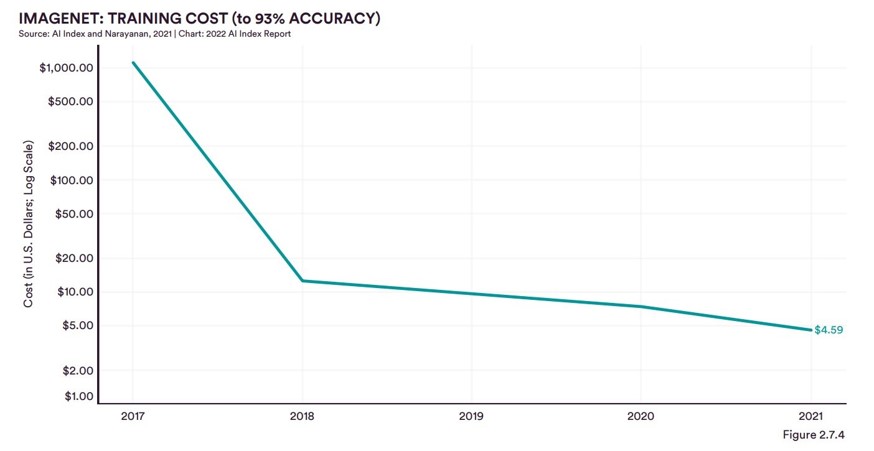
In 2010 a challenge named ImageNet Large Scale Visual Recognition Challenge (ILSVRC) was launched and in that challenge Imagenet dataset was introduced, ImageNet was the first large scale dataset that was used to properly demonstrate the power of modern neural networks. The ImageNet dataset is the first true large scale image dataset where we could check the performance of the Deep Neural networks developed in early stages of AI revolution. But before we go further, we must ask ourselves why it took almost two decades to create a dataset like ImageNet. The biggest challenge in creating a dataset is time, resources, and cost. For instance, the ImageNet dataset currently has around 14 million images belonging to 20,000 categories. Each image is labelled manually in the dataset. It would have taken years just to collect these images belonging to many classes, leaving alone their manual labelling. Dataset creation is a very time-consuming and costly process; thus, it took 20 years for AI to take off. Depending upon the model, it takes from a few hundred dollars to few thousand dollars to train on the entire Imagenet Dataset. On the other hand, labelling data is much more expensive, at the Silicon Valley startup Scale.ai (image below), dataset with sizes for 20k–50k will leave you with costs of up to $320’000 just for one dataset. In recent years there are better and cheaper data labelling tools but in no way, it has come close to training cost.
Challenges for current AI
It’s almost ten years since the release of VGG, it is a famous CNN architecture that first showed it was possible to do accurate image recognition with a deep network and small convolutional filters .. Since then, we have come a long way in the model architecture development and creating new and diverse datasets. VGG was the first network that achieved a decent performance on ImageNet challenge (classification on ImageNet dataset) and kickstarted the field of AI for the masses. VGG inspired a whole new series of architectures but still there are only a handful of techniques and models that can actually work with smaller datasets. To this day, data remains the single biggest problem for almost every problem. There are handful of large-scale dataset that can be used to check new model architectures but finding industry specific data is almost as hard as it was 10 years ago. To somewhat mitigate the problem of large datasets, practical AI implementations uses the concept of transfer learning. According to Wikipedia, Transfer learning (TL) is a research problem in machine learning (ML) that focuses on storing knowledge gained while solving and applying it to a different but related problem.[1] For example, knowledge gained while learning to recognize cars could apply when trying to recognize trucks. This is achieved by reusing the layer except for a few last layers of the given model architecture. The initial layers of a model extract similar types of information from the images thus, by freezing those layers, we save time and resources. The layer except for a few last layers of the given model architecture. The initial layers of a model extract similar types of information from the images thus, by freezing those layers, we save time and resources.
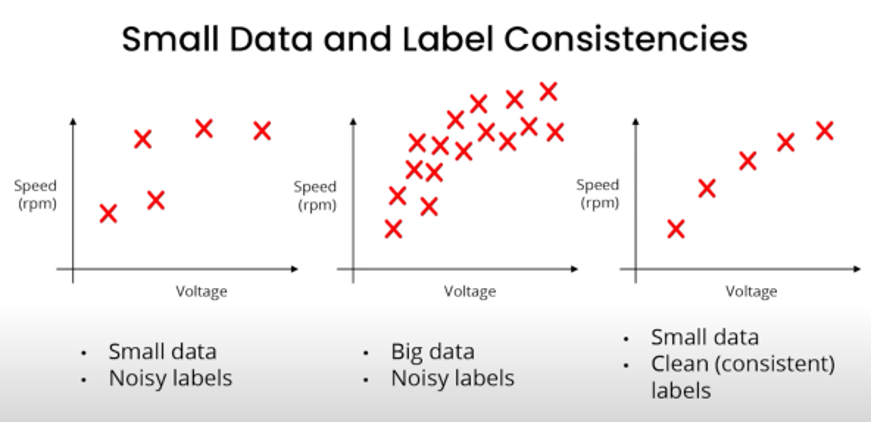
Not only do we need a lot of data, but the new wave is all about the good data.
There is a lot of data available on the internet, and most of it lies scattered, thus pretty much useless to us. Another challenge often faced by the industries is that the data available on the internet is mainly for creating a generalized AI model. The public data available on the internet is industry agnostic, thus pretty much useless for the industry. This is one of the primary reasons the industry runs quite behind in adopting AI compared to the academic world. Except for a few research companies like Google’s Deepmind and OpenAI, almost no company has the data to build systems that can scale. Due to proprietary rights, it becomes even tougher for most of the small-scale companies to get their hands on industry specific dataset. But in recent times, there have been few initiatives from companies like Google who are trying to create a more democratized world for data sharing thus enabling other small companies to build their own models and AI solutions.
But what is Good Data?
We’ve talked a lot about the importance of Data, but we still need to go one layer deep and talk about the details of data. Generally AI systems comprises of two main things Code and Data. In most of the problems outside consumer internet, Big Data doesn’t exist thus, we either need AI solution that can work with small datasets, or we need datasets that are clean and represents the distribution of the entire population set. In one of the recent talks by Dr. Andrew Ng (pioneer in AI), he talks about good data and why it is more important to have good data rather than big data. But let’s try to understand what good data is?
Good data:
- Covers the essential cases (good input distribution X). Sample population distribution should closely match the actual population distribution.
- Has accurate labels (High-quality y). Even a few wrong labels can significantly distort the learning capabilities of the model thus giving erroneous results in critical situations.
- Include timely feedback from deployment. To adapt model according to the change in dataset.
- Good governance (Reasonably free from bias; satisfies privacy; data provenance/lineage, regulatory requirements). To protect the privacy and prevent machines from becoming bias towards certain group of people.
A set of practices that aims to deploy and maintain machine learning models in production reliably and efficiently is called MlOps’. The word is a compound of “machine learning” and the continuous development practice of DevOps in the software field. MlOps’ most important task is ensuring consistently high-quality data in all phases of the ML project lifecycle.
Our approach
We at SkyeBase often work with industrial images; procuring any such data is always hard. SkyeBase deals with a wide variety of industrial images coming from sources like ports, oil rigs, bridges and many other industrial sites. For SkyeBase’s operation, the primary data source is our own collection through our different drones that can fly in different environments (inside, external, underwater, etc.). Even after all the available hardware, data collection is still hard. Often the data collected is not enough to build a scalable model. Depending upon the task at hand, sometimes we have to rely heavily on web scrapping for data collection. The main problem with data coming from scrapping is that it’s not clean and often contains low-quality images. The next big tasks in data handling are sorting and annotation. Currently, we are building our own annotation tool in order to set up a streamlined flow between our inspection platform I-Spect and the collected data. As SkyeBase expands its operation, we will create a data lake, in order to centralize all our data. To solve the problem of low resolution, SkyeBase uses the power of GANs (Generative Neural Networks). GANs are a particular kind of neural network that is capable of generating new data based on the gradient. GANs can be modified to generate new images, noise removal, or create super-resolution images. The data produced by super-resolution networks like REAL-ESR GAN is excellent and can be easily used for production-level systems. Using the super-resolution networks has been particularly helpful in SkyeBase’s operations.


Another idea we will soon incorporate into SkyeBase’s operations is using text-to-image generation models. With the recent launch of OpenAI’s DALL-E 2 and Google’s Imagen, we are optimistic that this is a beneficial method to create data for data-scarce problems. A few months ago, the State-of-the-art text-to-image was not up to the standard where it can be utilized to train models, but with the launch of OpenAI’s and Google’s systems, we are optimistic that this is where the future of data creation lies. Another advantage of using such a system is that it automatically takes care of data privacy and security. Text-to-image systems are still in the testing phase, and their exact usefulness is yet to be discovered in a full-scale production system.
If you are interested in knowing about drone Inspection and the technology we use, click here.
Vishal Rajput – AI-Vision Engineer at SkyeBase
